
A successful file structure organizes your data and code with the goal of repeatability, making it easier for you and your collaborators to revisit, revise and develop your project. File structures are not fixed entities, but rather build a framework that communicates the function and purpose of elements within a project by separating concerns into a hierarchy of folders and using consistent, chronological, and descriptive names.
Begin with something simple and clear to avoid bogging down at the start, and allow the structure to evolve as needed.
| Contents |
Why file organization matters
Consistency matters. Like navigating around the house, it’s nice to know where everything is and that items are placed in a logical order (hopefully your kitchenware isn’t found in your bathroom). The same holds true for coding. Knowing where files are, when to use certain code for certain operations, and how to find associated results, data, and figures can not only streamline productivity, but also allow for consistency (even across multiple projects) and shareability.
Where you place your files and how you organize your file structure can be seen as an overall map to your coding projects. As with a map legend, you should establish a set of expectations about where to find parts of the project, and in which order these parts fit (i.e., run) together.
Why do it: for others
Even if you are working on a class assignment, it is best to work under the mindset that your work will be shared and reproduced by others. For that to happen, you need to organize your code such that newcomers can quickly access key parts of your project without looking through documentation or aimlessly clicking through files. In a way, you want others to thank you. They will hopefully thank you for:
- the time saved in learning your project structure
- being able to collaborate more easily with you
- quickly learning how your analysis was performed
- being able to quickly reproduce your code, which adds confidence to both the collaborator and you.
Why do it: for you
If you’ve ever organized your desk to clean up both physical and mental space, then your coding projects deserve the same consideration. The time invested in learning how to organize your code now will help you streamline future projects and add consistency between projects. Even if you are working on a quick homework assignment, think about the hundreds of similar homework assignments for which you have to mock up a folder and then finagle some files (we advise against putting everything on your desktop). So whether you’re working on small or big projects, setting a standard structure will add consistency among all of your work and decrease the amount of time it takes to boilerplate your code.
{kind=link}
Why do it: for the future you
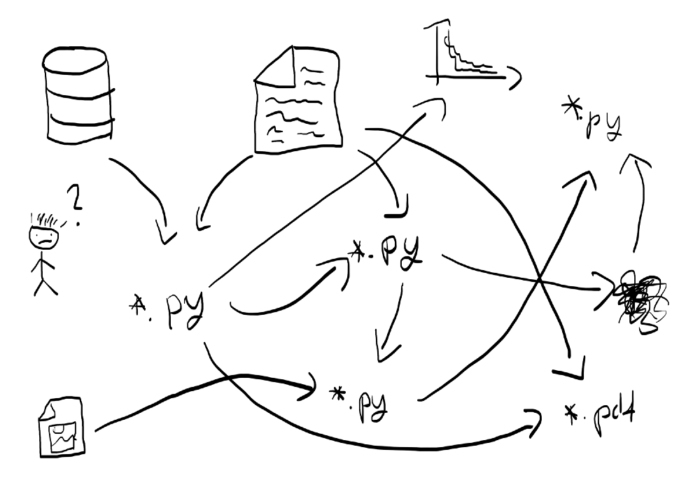
^ this sucks
Being confused is never fun, especially when you are the cause of confusion. Going back to the code and forgetting where your files are placed, or worse, which files to use (the deadly trial-and-error approach of using file1.py, file-v1.py, file-mod1.py, or file-try-this-one-v1.py suffixes) makes for a gruesome experience. Even worse, it will limit the ability to reproduce your code.
Therefore, establishing consistency at the beginning – which starts with a standard file structure and naming convention – will pay dividends for your future self. The goal is to thank your past self.
Getting started
Some terminology:
- Folders and directories are used interchangeably. Folders will be used hereon.
- File structure, file hierarchy, and file schemas are used interchangeably. File structure will be used hereon.
Establish the right perspective: Identify your goals and audience
As with writing an article or making a presentation, deciding how to deliver key information depends not only your personal goals, but also on the goals of your audience. That being said, to establish a perspective for the sake of the below examples, we are going to assume you are a data scientist. We use a loose definition of a data scientist:
- You work with some sort of data: binary, text, web, images, video, machine data…
- You will modify the data to meet your needs
- You will analyze the data and make conclusions
- You will create representations of such conclusions: charts, figures, images, videos…
- You will share some or all of the above processes with others, whether by turning in an assignment for class, or publishing results with a conference or journal
Those viewing your code, who may be data scientists, researchers, or those wanting to learn, may have other intentions, such as…
- Finding your datasets to repeat and confirm your results and methodologies
- Finding your datasets so they can perform their own analysis
- Using your source code to help analyze their work, or fork it for other purposes
- Looking at your results and figures
A state of mind: Not everything has to be set in stone.
Finding the right time to deviate and be flexible in establishing a file structure is wiser than blindly adhering to ritual. A relevant saying now popularized in the coding world is,
“A foolish consistency is the hobgoblin of little minds.” — Ralph Waldo Emerson (and PEP8 style guides)
None of the practices we describe below are binding, or necessary to make good code. Rather, we try to articulate general principles for achieving consistent, maintainable file structure.
There are also tradeoffs between the time to develop such file structures, and time to actually write and implement code. As Donald Knuth, one of the early leaders of good programming, has said,
“Premature optimization is the root of all evil (or at least most of it) in programming.” — Donald Ervin Knuth
The goal isn’t to make the gold standard of coding practices (but if you do come up with one, please share). Rather, we hope you’ll find this a useful combination of principles to apply and tools to adapt to your specific needs.
Best practices for file structures
There are some overarching ground rules to keep in mind before hacking away at your computer. They are:
- Do not modify your raw data manually, or even better, at all.
(Don’t give in to the temptation of opening a raw dataset in Excel and changing values.) - Data manipulation should work like a conveyer belt: it stops at checkpoints. E.g., it gets modified/cleaned/analyzed, and then it moves on.
- Code of different quality (scratch work vs. compiled binaries) should be separated.
- Always have collaborators in mind, even if there is a 0% chance of getting collaborators. Work towards shareable code. Have public awareness. In a way, imagine if your code were to be released on GitHub right now.
- Use relative file paths, not absolute paths, to facilitate shareability.
- Consistency (within your project) is key.
Best practices for separation of concerns
When writing code, it is a good design principle to separate program functionality into distinct sections, where each section addresses a separate concern (e.g. reformatting data to plot a figure). This is also true when breaking down your file structures: each folder should contain files with similar functionality or purposes.
| Data |
|
| Raw data |
|
| Edited data |
|
| Finalized data |
|
Best practices for experimental and scratch work
To help keep track of this process, every scientist should have a lab notebook.
| Definitely include | Maybe include |
|
|
As you develop your project, scratch work will sprout up alongside your lab notebook. Scratch work is anything you do to transform, manipulate, or inspect (plot, explore, analyze, etc.) the data as it moves from station to station along the conveyor belt.
Always put everything into scripts to ensure repeatability, even though it may seem quick and easy to do with command line arguments in the moment. Consider later on, when you’re communicating that manipulation to a collaborator. It’s more challenging and error-prone to say, “Do these 15 commands, changing argument x to y,” versus “Run this script.” Even if you don’t have collaborators, imagine you have to recall an intermediate plot to convince your advisor of your reasoning. It will undoubtedly be easier to just pull up a MATLAB/Python script and run it without worry.
Source code: Put it somewhere logical.
By source code, we mean the finalized working code that is used to derive the results. Depending on the size and nature of your project, there may also be several single-use scripts for tasks such as converting, cleaning, plotting, and so on. Whether these scripts are included in the src folder as final working code or distributed in other folders as scratch work is mostly a matter of personal preference, as long as it’s logical to find them later. Sticking to the house analogy, it’s reasonable to look in your kitchen and bathroom for cleaning supplies.
Results: Keep them separate.
Whatever format your results are (figures, a code/executable, data to be passed onto another project, even a paper draft), keeping them separate allows quick access when you need to evaluate your conclusions.
Consider using Makefiles.
Especially for larger projects, Makefiles will aid in tracking revisions in your code and data. (Google and Makefile templates are your friends.)
Choose a file structure that matches the scale and aims of your project.
All good structures contain at least the following elements:
- A unique main folder for the project
- Some form of code
- Some form of data
- A readme document with any important information about the project for yourself or collaborators
Start by sketching out a base structure.
- Ground zero: make a unique folder for the project.
- Determine the scale of the project. Somewhere between quick visualization and long-term collaborative project? This will give a hint at how complex the file structure should be.
- Identify the parameters distinguishing data. Someone looking at your files should be able to recognize those parameters when looking at both your file structure and filenames.
- Assess the easiest way to access the data. Often, this will be set by the most important distinguishing variable between data sets (e.g., chronological, machine/sensor type, experiment, human subject, learning model, etc.). Keep things simple and clear to start, so it’s easy to inspect and debug. Worry about cleverness and optimizing once you verify things are working.
Case studies: Different file structures are suited to different needs.
- Is this a small assignment that requires a quick output? See Case Study 1: almost flat.
- Is this an exploratory project, where there may not even be results given the uncertainty of the data and results? See Case Study 2: a simple hierarchy.
- Is this is a huge collaborative project which you expect to drive several distinct results sections, and possibly multiple manuscripts/publications? See Case Study 3: a complex hierarchy.
Best practices for naming conventions
It’s easy to be overwhelmed by the sheer variety of naming conventions. However, there are a few important base principles on which you can build your own.
- Be descriptive and avoid ambiguity, particularly with versioning (e.g., try “
-v2“, not “_final_final“) - Keep names concise.
- Abreviations are helpful, but make sure you define them in a
readme. - Use context (e.g. parent folders) to avoid redundant/lengthy names.
- Abreviations are helpful, but make sure you define them in a
- There is only one way to format a date: YYYY_MM_DD (e.g. 2019_07_04). Your operating system will automatically sort this style chronologically.
- Similarly, always pre-pad smaller numbers with zeros in a sequence (e.g. 01, 02,…,10 if instead of 1, 2, 3,…,10).
- As always, be consistent within your project. If your group already has an established style, start there, and tailor it to your needs.
Construct a file path sentence that helps users identify the file.
Every file, whether it be data or code, has a path (including the filename at the end) that tells the computer where to look for it. The path is also a “sentence” that tells the human user the information needed to identify the file. Separate this information into individual “idea elements,” which may be a single character or number, a word, or a short phrase (e.g. a subject’s first and last names).
Folder names are, in general, are a single idea element. Filenames, on the other hand, may be one or more ideas. Take, for example, a raw data filename from the flat structure case study, weatherStation_MITGreenBuilding_2019_07_01.csv. There are three idea elements here:
| Idea 1 | Idea 2 | Idea 3 | |
| General idea: | Sensor type | Geographic location | Date recorded |
| Details: | weatherStation |
MITGreenBuilding |
2019_07_01 |
For a more involved example using multiple idea abbreviations, see this case study by the Stanford Libraries.
Ordering the ideas: Choosing descriptive vs. chronological depends on what’s most important.
So far, we’ve discussed a lot about the morphology of the file structure, but not much about the order of the ideas. Should it be date, then location – or location, then date? That all depends on how you will be accessing the data.
In general, put the most important thing first, whether in a folder hierarchy or an individual filename. (Individual filenames start mattering more for flatter file structures: e.g., if you only have raw, clean, final data or even a completely flat structure.) If the project goal is to identify temporal variations in weather data, put the date first in the path sentence (left-most, highest-level). If you’re tracking spatial variations in atmospheric methane averaged over time, it may make more sense to start with location.
The last idea to be addressed is often the version number. Use a simple version sequence (e.g. _v1, _v2, _v3) to avoid the chaos of _final, _finalfinal, _reallyfinal, _test_final_use_this_one. If someone handed you files like this, would you trust the conclusions? Would you feel they did a good job with the project?
Separating the ideas: Underscores, camelCase, periods or hyphens each have advantages.
To prevent ideas from blurring together, some form of delimiter is needed. The OS already put slashes in between folder names for us, but what if we have multi-word ideas or multi-idea filenames?
- Underscores (
_) and camelCase (firstNameLastName) are probably the two most common delimiters because they are interoperable with nearly all modern operating systems and coding languages. They are robust and unlikely to give you trouble when sharing your project. - Periods (
.) are often overlooked as delimiters by many, perhaps because they serve to separate the file extension at the end of the file. However, modern operating systems ignore all but the last period for this purpose, so they are safe to use. While you may need to be careful to avoid bugs with certain languages that could confuse periods for operators (MATLAB, Python), they have a major benefit if you’re doing any work by hand. When you double click on a segment of a name to highlight, periods separate highlight regions, as opposed to being overrun (see below). - Hyphens (
-) are also quite common, visually similar to an underscore, and are easily handled by most operating systems. But they have one potential issue: if you’re not careful in your code, they can be confused for minus signs. Depending on your operating system, hyphens may behave like a period when double-clicking to highlight (e.g., it does for Mac OS, demonstrated below).
| Delimiter | Example + highlighting behavior |
Underscore _ |
 |
camelCase |
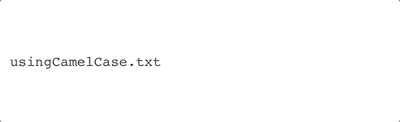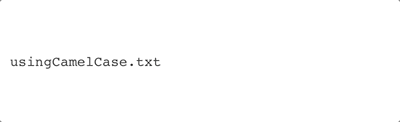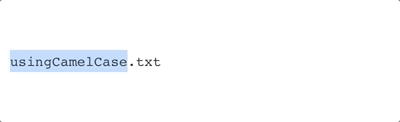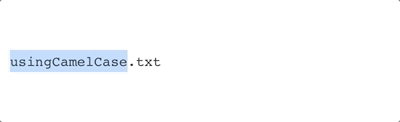 |
Period . |
 |
Hyphen - |
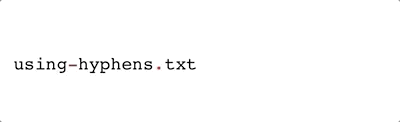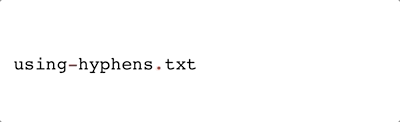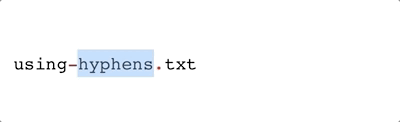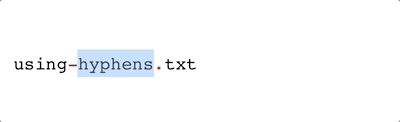 |
Mixing delimiters can be a great strategy for improving readability. Consider these two filenames:
20190701.GeorgeSun.v1.csv20190701_davidLarson_v1.csv
The general ideas are are date, subject name, and version number. In both cases, a primary deliminator is used to separate the ideas, while camelCase is used to make the names easier to read.
A last note on delimiters: never use spaces in your project path and filenames. Yes, many of us use them in our computer’s general file system because they’re so intuitive. But code and operating systems have a hard time dealing with them, so avoiding them in your project file structures will save you a lot of headache and cumbersome code.
Appendix: Useful references
Here we share other viewpoints that have inspired this guide.
- Style guides
- File structure templates
- Management and organization guides
- “A Quick Guide to Organizing Computational Biology Projects,” William Stafford Noble, PLoS Computational Biology
- “Data Management Best Practices,” Axiom Data Sciences
- “Four Strategies for Organizing Code,” Martin Sandin, Medium
- “Manage Your Data Science Project in Early Stage,” Edward Ma, Towards Data Science
- “Tips, Tricks, and Philosophies on Computational Work,” Claire Duvallet, MIT PhD Alum
- Stackoverflow Q&A